Scraping Data
Tue, Apr 14, 2020
Readings
Launch Google Sheets
You can start a new Google Spreadsheet at the following URL:
First, let’s explore the Website for Amador County Health Department.
https://www.amadorgov.org/services/covid-19/-fsiteid-1
Type in the following formula to cell A1:
=importhtml("https://www.amadorgov.org/services/covid-19/-fsiteid-1", "table", 1)
Next, let’s scrape a website using Xpath.
Visit:
https://www.cisionjobs.co.uk/jobs/journalist/
When told to, we will type in the following:
=importxml("https://www.cisionjobs.co.uk/jobs/journalist/","//*[@id='listing']")
Visit Google Collab
We’ll start by using Google Collab at the following URL:
https://colab.research.google.com/
You’ll need to use your Google Account to log in.
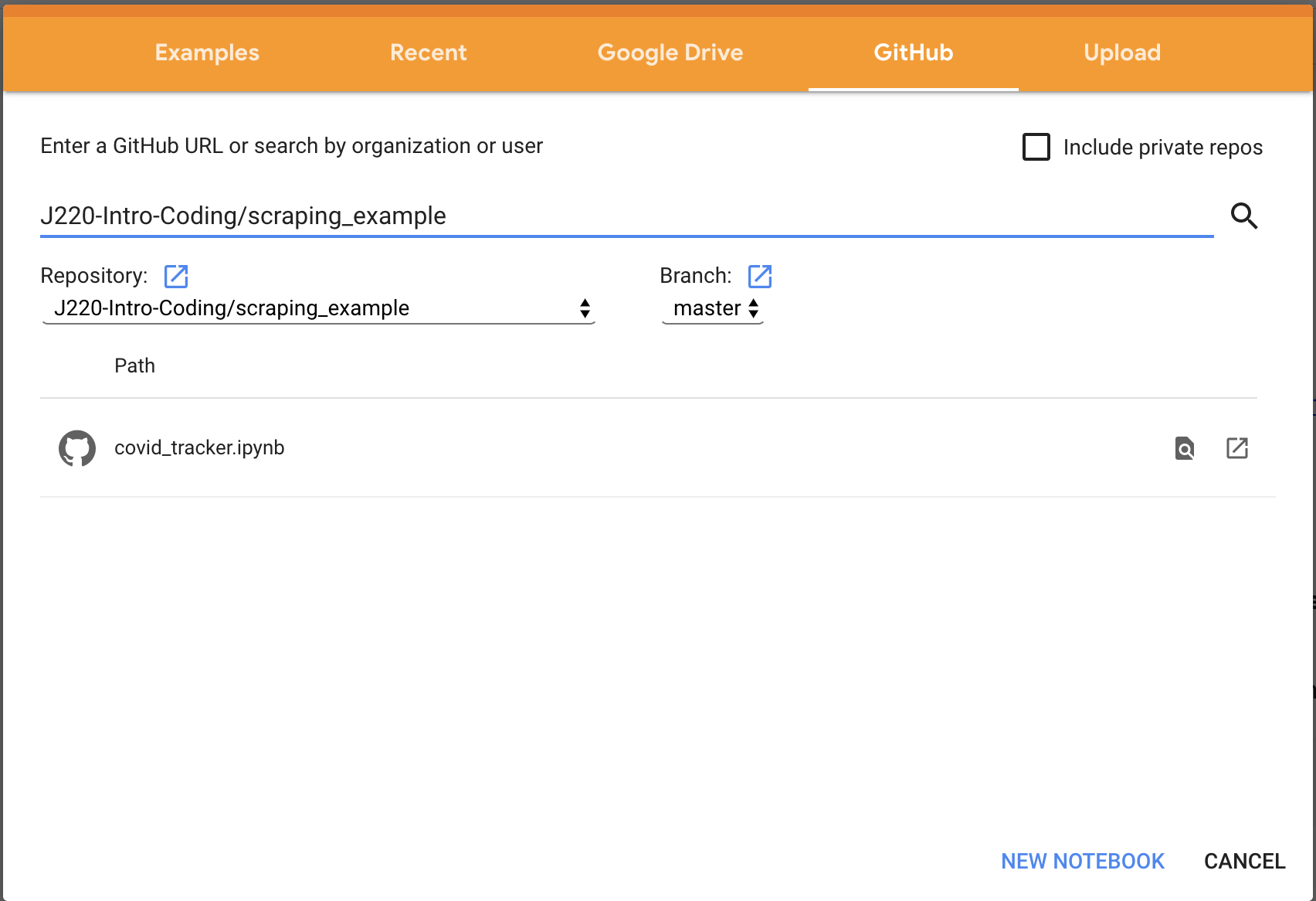
Search for the Jupyter Notebook I’ve setup
Click the Github tab, and search for J220-Intro-Coding/scraping_example.
Answer to the Butte example
During the in-class exercise, I will go over how to parse the website to locate the appropriate content. We will arrive at the following together.
soup.find_all('table')[3].find_all('td')[1].text.strip()
soup.find_all('table')[3].find_all('td')[3].text.strip()
To download your files from Google Collab
from google.colab import files
mycsv.to_csv('myfile.csv')